고루틴의 동작 원리에 관하여
고루틴?
고루틴은 GO언어에서 프로그램의 동시성을 쉽게 구현하고 기존의 단순 스레드 기반의 구현에 비해 효율적인 동작을 수행해 내기 위해 만든 작업단위 이다.
고루틴의 장점
아래 내용에 들어가기에 앞서서 스레드에 관해 정리해야할 부분이 있다.
CPU의 멀티스레딩에 활용되는 용어인 스레드와 아래에서 설명될 OS영역에서 다뤄지는 스레드는 서로 지칭하는 대상이 다르다.
CPU의 스레드는 한개의 코어를 OS에게 여러개로 인식시켜 동작하도록 하는 하드웨어 영역의 개념이고, 아래에서 계속하여 언급할 스레드는 OS 하위의 소프트웨어 영역에서 CPU의 작업단위로 지칭되는 용어이다.
메모리 소비
고루틴은 스레드에 비해 더 작은 메모리만 필요로 함. 고루틴 생성에는 2KB의 스택만 필요로 하고 필요에 따라 힙을 사용.
반면 스레드는 스택 간 메모리 Guard _page_을 하는 공간을 포함하여 1MB 정도의 스택을 필요로 함.
→ 서버로 들어오는 요청당 하나의 고루틴을 만드는 것에 대해 무리가 없지만, 요청당 하나의 스레드의 경우 OOM으로 이어지기 쉽다.
생성 및 소멸에 필요한 비용
스레드는 OS에 리소스(메모리)를 요청하고 다 사용하면 반환해야 하기 때문에 상당한 생성, 소멸 비용이 들어감. 스레드 풀을 이용하면 어느 정도는 문제를 해결할 수 있기는 함.
이와 대조적으로 고루틴은 Go 런타임에 의해 생성 및 소멸되며 매우 적은 비용으로 이루어짐.
컨텍스트 스위칭 비용
기본적으로 프로세스 레벨의 컨텍스트 스위칭이 프로세스 내부 스레드간의 컨텍스트 스위치 비용보다 비싸다. 이유는 컨텍스트 전환 시 처리해야 하는 데이터의 양이 훨씬 많기 때문이다.
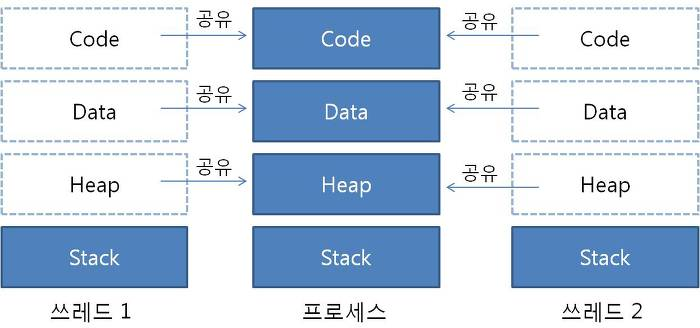
고루틴에서 컨텍스트 스위칭(?)이 발생하는 경우에는 스레드의 경우보다도 훨씬 적은 정보를 처리하기 때문에 더 비용이 적다는 점은 말할 필요도 없다.
컨텍스트 스위칭 이라는 단어는 기본적으로 프로세스/스레드 레벨의 작업단위를 cpu코어가 연산하며 전환할때 이용되는 용어이기 때문에 고루틴에 사용하기에는 부적절한 부분이 있긴 하다.
하지만, 중요한 점은 단순히 전환에 필요한 정보의 양이 적다는 수준이 아니다.
고루틴이 프로세스/스레드의 컨텍스트 스위칭과 근본적으로 빠를 수 밖에 없는 부분은 스위칭 과정에서 커널<->유저 모드의 전환이 일어나지 않는다는 점이다.
아래는 컨텍스트 스위칭이 일어날때 기본적으로 OS가 수행하는 로직을 대략적으로 설명한 내용이다.
- 유저프로세스 A 가 커널모드로 진입하면서 유저모드 레지스터 컨텍스트를 A 의 커널스택에 저장
- 프로세스 A 는 커널컨텍스트를 가진상태로 Schedule 을 호출
- A 의 커널컨텍스트가 메모리에 저장되고 프로세스 B 의 저장된 커널컨텍스트를 레지스터에 복원
- B 의 커널컨텍스트가 메모리에 저장되면서 B 의 유저컨텍스트를 레지스터에 복원하면서 유저모드로 리턴

여담이지만, 고루틴과 같이 OS레벨이 제공하는 스레드의 개념을 넘어서 유저모드에서만 전환되는 작업단위들을 지칭하여 Green thread라고 부르는 기술 용어가 있다.
위키피디아에 따르면 이러한 Green thread의 범주에 속하여 동시성 프로그래밍을 지원하는 언어는 go만 존재하는 것이 아니다. (python, erlang, haskell, lua, perl, ruby, rust …)
물론 그렇다고 고루틴이 위에 기술한 언어들과 비슷한 수준이냐고 묻는다면, 이 중에서도 상당히 높은 차원의 추상화와 아키텍쳐를 통해 압도적으로 높은 성능과 사용의 편의성을 제공한다. (그러니까 유명하지)
Go Runtime Scheduler
goroutine 은 Runtime Scheduler 에 의해 관리된다. Runtime Scheduler 는 Go 프로그램이 실행되는 시점에 함께 실행되며, goroutine 을 효율적으로 스레드에 스케줄링 시키는 역할을 수행한다.
아래와 같은 원칙을 가지고 동작한다.
- 커널 스레드는 비싸기 때문에 되도록 작은 수를 사용한다.
- 많은 수의 goroutine 을 실행하여 높은
Concurrency를 유지한다. - N 코어 머신에서, N 개의 goroutine 을
Parallel하게 동작시킨다.
GMP 구조체
- G (Goroutine) : 고루틴
- 런타임이 고루틴을 관리하기 위해서 사용
- 컨텍스트 스위칭을 위해 스택 포인터, 고루틴의 상태 등을 가지고 있음
- P (Processor) : 스레드에 반인딩 되는 논리적 프로세서
- 최대 GOMAXPROCS개를 가질 수 있음
- P는 컨텍스트 정보를 담고 있으며, LRQ를 가지고 있어서
G를M에 할당하고 관리함
- M (Machine) : 스레드
- LRQ(Local run queue) :
P마다 존재하는 Run QueueP는 LRQ로 부터 고루틴을 하나씩 POP하여 실행LRQ가M에 존재하지 않는 이유는M이 증가하면 LRQ의 수도 증가하여 오버헤드가 커지기 때문P마다 하나의 LRQ가 존재하기 때문에 레이스 컨디션을 줄일 수 있음
- GRQ(Global run queue) : LRQ에 할당되지 못한 고루틴을 관리하는 Run Queue
- 고루틴이 생성되는 시점에 모든 LRQ가 가득찬 경우 GRQ에 고루틴이 저장

스케줄러 동작 컨셉들
본격적인 동작 컨셉들을 알아보자.
1.Reuse threads
Runtime Scheduler(이하 스케줄러)는 고루틴이 필요할 때 스레드를 생성한다. 그런데 생성된 스레드에 더이상 실행할 고루틴이 없게 된다면? 스레드를 생성/종료할 때에도 시스템콜이 필요하게 되며, 자원의 할당/반납의 과정에서 부하가 발생한다. 스케줄러는 이렇게 생성된 고루틴이 종료된 뒤에도 일정시간 반납하지 않고 idle 상태로 관리하다가 새로운 고루틴에게 빠르게 할당해 줄수 있다.
그런데 만약 모든 스레드가 고루틴을 처리하는 동안에도 고루틴이 계속해서 만들어진다면 어떻게 될까?
2.Limit threads accessing runqueue
GO에서 스케줄러가 생성할 수 있는 스레드 최대 수는 기본적으로 10000개로 되어 있다. 하지만 그것이 동시에 실행 가능한 고루틴의 수는 아니다. 위 GMP모델에서 스레드가 M에 해당했다면, M 에 G를 할당하여 동작을 관리하는 실질적인 기능을 수행하는 P 는 기본적으로 CPU 코어 갯수로 제한된다(runtime.GOMAXPROCS를 활용하여 수를 조절할 수도 있긴 하다). 그렇기 때문에 위에서 우려했던, 고루틴이 무한정 과도하게 많은 스레드를 생성하여 할당받는 상황은 걱정하지 않아도 된다.
3.Distributed runqueues
LRQ는 P에 하나씩 할당된다. 그렇기 때문에 동시에 여러 고루틴이 여러 스레드에 할당되는 과정을 스케줄링 할때 GRQ만 존재하게 되었을때 발생할 수 있는 mutex(스케줄락)을 최소한 시킬 수 있다.
그리고 특정 LRQ가 빠르게 소비되어 더이상 수행할 고루틴이 없게 된다면 연결된 스레드를 놀게 하거나 종료시키는 것이 아니라 다른 P이 LRQ의 고루틴들을 절반 뚝 떼어와 가져오거나, GRQ의 고루틴을 가져와서 실행하는 똑똑한 로직도 있다.
참고로, 과거 GO가 1.0 버전이었을 때에는 GMP모델이 아닌 GM 모델이었는데, 당연히 LRQ가 별도로 존재하지 않아서 위에서 말하는 mutex로 인한 성능저하가 꽤 있었다고 한다.
4.Blocking System call
위에서 설명하는 내용에 따르면, 동시에 실행될 수 있는 고루틴과 스레드의 수는 GOMAXPROCS에 따라 결정되는 P 에 의해서 결정되는 것이니까 동시에 실행되는 G = M갯수 = P갯수 일까? 아니다
G와 M은 P보다 많은 수가 동시에 할당되어 실행 될 수 있다. 그렇다면 어떨 때 P보다 많은 G와 M이 존재할 수 있는 걸까?
바로 system call이 고루틴 내에서 수행되어 고루틴이 할당된 스레드가 blocking되었을 때이다.
P는 M이 블로킹 된 것을 감지하면, idle 상태의 M을 가진 P의 LRQ로 본인이 소유한 LRQ의 고루틴을 할당하거나 idle상태의 M이 없다면 새로운 M(스레드)를 생성하여 고루틴을 할당한다.
실제로 아래와 같은 코드를 실행하면, 1002개의 스레드가 생성되어 실행되는 것을 볼 수 있다.
package main
import (
"fmt"
"syscall"
)
func block(c chan bool) {
fmt.Println("block() enter")
buf := make([]byte, 1024)
_, _ = syscall.Read(0, buf) // block on doing an unbuffered read on STDIN
fmt.Println("block() exit")
c <- true
}
func main() {
c := make(chan bool)
for i := 0; i < 1000; i++ {
go block(c)
}
for i := 0; i < 1000; i++ {
_ = <-c
}
}

엥? 그런 논리라면 system call이 발생하는 모든 고루틴들은 스레드를 찍어내는 걸로 동시성을 구현한다는 건데, 그럼 결국에 모든 고루틴들이 system call을 활용하면 고루틴을 쓰는 효과가 없는거 아닌가?
맞는 말이지만 그렇지 않다.
Go에 구현된 라이브러리들 중 system call로 간주되어 스레드를 블로킹 할 것 같은 기능을 수행하는 대부분의 것들(socket I/O, waiting timer, file I/O …등)은 OS에서 제공하는 select, poll, epoll, kqueue 등의 기능을 통해 I/O 멀티플렉싱을 수행하고, 덕분에 블록킹 하지 않고 system call을 수행해 낼 수 있도록 설계되어있다.
아래의 코드는 고작 11개의 스레드를 사용하여 동작한다.
package main
import (
"fmt"
)
func block(c chan bool) {
fmt.Println("block() enter")
var s1, s2 string
n, _ := fmt.Scan(&s1, &s2)
fmt.Println("입력 개수:", n)
fmt.Println("block() exit")
c <- true
}
func main() {
c := make(chan bool)
for i := 0; i < 1000; i++ {
go block(c)
}
for i := 0; i < 1000; i++ {
_ = <-c
}
}
이러한 방식으로 생성된 스레드들은 다중코어 환경을 지원하기 때문에 궁극적으로 고루틴을 사용하면 간단하게 동시성/병렬성을 만족하는 프로그램을 개발할 수 있다.
결론은 고루틴을 사용하더라도 아무 생각없이 고루틴 내부에서 시스템콜을 난발하는 로직을 작성하면 일반 멀티쓰레드 다중화랑 성능이 다를게 없다는 것이 결론이다.
GO에서 자체적으로 제공하는 라이브러리에서 사용할 수 있는 함수들이라도, 어쩔수 없이 시스템콜을 활용해야하는 경우들도 다수 있는데, 이런 함수들에 대해서 인지하고 활용 스레드에 대해서 검사하는 습관을 길러야겠다.
참고자료
- https://stackoverflow.com/questions/48638663/what-is-relationship-between-goroutine-and-thread-in-kernel-and-user-state
- https://stackoverflow.com/questions/24599645/how-do-goroutines-work-or-goroutines-and-os-threads-relation
- https://dave.cheney.net/2015/08/08/performance-without-the-event-loop
- https://groups.google.com/g/golang-nuts/c/2IdA34yR8gQ
- https://go.dev/doc/effective_go#goroutines
- https://stackoverflow.com/questions/15983872/difference-between-user-level-and-kernel-supported-threads
- https://en.wikipedia.org/wiki/Green_threads
- https://velog.io/@kineo2k/%EA%B3%A0%EB%A3%A8%ED%8B%B4%EC%9D%80-%EC%96%B4%EB%96%BB%EA%B2%8C-%EC%8A%A4%EC%BC%80%EC%A4%84%EB%A7%81%EB%90%98%EB%8A%94%EA%B0%80
- https://github.com/golang/go/blob/master/src/runtime/runtime2.go
- https://velog.io/@kineo2k/Go%EC%9D%98-%EB%8F%99%EC%8B%9C%EC%84%B1-%EA%B5%AC%EC%84%B1-%EC%9A%94%EC%86%8C
- https://sungjunyoung.github.io/posts/how-goroutine-works/
- https://segmentfault.com/a/1190000040092613/en